
Ứng dụng trí tuệ nhân tạo trong dự báo chỉ số giá tiêu dùng CPI
TCDN - Nghiên cứu ứng dụng Trí tuệ nhân tạo, cụ thể là mạng nơ-ron nhân tạo, nhằm dự báo chỉ số giá tiêu dùng (CPI) ở Việt Nam. Tập dữ liệu bao gồm 7 biến đầu vào và một biến đầu ra là chỉ số CPI được thu thập từ năm 2002 đến năm 2022.

TÓM TẮT:
Nghiên cứu ứng dụng Trí tuệ nhân tạo, cụ thể là mạng nơ-ron nhân tạo, nhằm dự báo chỉ số giá tiêu dùng (CPI) ở Việt Nam. Tập dữ liệu bao gồm 7 biến đầu vào và một biến đầu ra là chỉ số CPI được thu thập từ năm 2002 đến năm 2022. Mô hình sau khi huấn luyện được đánh giá qua các biểu đồ trực quan nhằm so sánh giữa giá trị thực trong tập dữ liệu và giá trị dự đoán. Hơn nữa, giá trị sai số bình phương (MSE) được sử dụng để đánh giá hiệu quả mô hình trên Tập huấn luyện và cả Tập kiểm tra. Kết quả trên hai tập dữ này đạt giá trị lần lượt là và . Kết quả so sánh trực quan và giá trị MSE cho thấy mô hình sau khi huấn luyện đạt hiệu quả cao trong việc dự báo và có tiềm năng ứng dụng trong thực tế.
1. Giới thiệu nghiên cứu
Các chỉ số kinh tế là thước đo quan trọng giúp đánh giá đầy đủ, toàn diện tình hình phát triển kinh tế - xã hội ở mỗi quốc gia. Các chỉ số này còn có tầm quan trọng trong việc xây dựng chính sách và tiền tệ của chính phủ trong và ngoài nước (Dinh, 2020; Nyoni, 2019). Trong đó, chỉ số giá tiêu dùng (Consumer Price Index - CPI) là một trong những chỉ số quan trọng (Bryan and Cecchetti, 1993). Chỉ số này phản ánh xu hướng và mức độ biến động giá theo thời gian của các mặt hàng trong rổ hàng hóa và dịch vụ tiêu dùng. Chỉ số này giúp các nhà điều hành có cái nhìn rõ ràng về tác động của các chính sách kinh tế đến đời sống xã hội.
Theo (Nahm, 2015), việc dự báo CPI ngày càng trở nên phức tạp do sự biến động không ngừng của nền kinh tế toàn cầu. Chính vì vậy, việc áp dụng các mô hình và phương pháp mới trong dự báo CPI là điều cần thiết. Nhiều mô hình xác suất thống kê khác nhau đã được áp dụng để dự báo CPI. (Álvarez-Díaz and Gupta, 2016) đã sử dụng mô hình bước ngẫu nhiên (random walk) và mô hình tự hồi quy bậc 1 (AR(1)) để dự báo CPI của Mỹ. Al-Tamimi và cộng sự đã sử dụng mô hình hồi quy bội để dự báo CPI của UEA giai đoạn 1990 - 2005 (Al-Tamimi et al., 2011). Trong nghiên cứu (Hu et al., 2013), tác giả đã sử dụng thuật toán thống kê để dự báo CPI. Bernardi và cộng sự sử dụng phương pháp dự báo Holt - Winter để dự báo CPI của Italia giai đoạn 2004 - 2014 (Bernardi and Petrella, 2015). Tuy nhiên các nghiên cứu này đạt độ chính xác chưa cao và chưa phân tích được tác động của các yếu tố đầu vào đến việc dự báo CPI.
Gần đây, các nhà khoa học tập trung vào việc kết hợp các mô hình thống kê và Trí tuệ nhân tạo nhằm dự báo chỉ số CPI chính xác và đáng tin cậy hơn. Chẳng hạn như, Riofrío và cộng sự đã sử dụng mô hình SARIMA kết hợp với 2 mô hình Trí tuệ nhân tạo là Support Vector Regression (SVR) và Long Short-Term Memory (LSTM) để dự báo CPI của Ecuador (Riofrío et al., 2020). Bộ dữ liệu được sử dụng bao gồm 174 mẫu, được thu thập từ tháng 1 năm 2005 đến tháng 6 năm 2019. Kết quả cho thấy rõ ưu thế vượt trội của các mô hình Trí tuệ nhân tạo: mô hình SVR có hiệu suất tốt nhất với MAPE là 0,00171, tiếp theo là mô hình LSTM với MAPE là 0,00173. Mặt khác, trong nghiên cứu (Peirano et al., 2021) nhóm tác giả đã kết hợp hai mô hình SARIMA và LSTM trong việc dự đoán tỷ lệ lạm phát ở năm nền kinh tế mới nổi ở Mỹ Latinh bao gồm: Brazil, Mexico, Chile, Colombia, Peru. Thời gian nghiên cứu là từ tháng 1 năm 1958 đến tháng 6 năm 2019.
Trong bối cảnh hậu dịch COVID-19, nền kinh tế đối mặt với nhiều rủi ro tiềm ẩn như: cơ cấu ngân sách, rủi ro bắt nguồn từ môi trường xã hội và thể chế. Cùng với đó là sự bùng nổ của ứng dụng Trí tuệ nhân tạo trong các lĩnh vực kinh tế - xã hội cho thấy tiềm năng to lớn của công nghệ này. Việc ứng dụng Trí tuệ nhân tạo trong tất cả các lĩnh vực kinh tế - xã hội trở thành nhu cầu cấp thiết. Trong lĩnh vực kinh tế, cụ thể là dự báo chỉ số CPI, các nước trên thế giới không ngừng cập nhật và đổi mới mô hình dự báo. Tuy nhiên, ở Việt Nam việc ứng dụng Trí tuệ nhân tạo trong dự báo chỉ số CPI chưa nhận được sự quan tâm đáng kể. Việc xây dựng một mô hình phù hợp với đặc thù kinh tế Việt Nam với độ chính xác và tin cậy cao trở nên cần thiết.
2. Tập dữ liệu chỉ số giá tiêu dùng
2.1. Tập dữ liệu
Tập dữ liệu chỉ số CPI của Việt Nam được thu thập bởi Tổng cục thống kê Việt Nam từ tháng 1 năm 2002 đến tháng 12 năm 2022. Tập dữ liệu gồm có 7 biến đầu vào bao gồm: lương thực, thực phẩm, đồ uống và thuốc lá, nhà và vật liệu xây dựng, đồ dùng gia đình, giáo dục, hàng hóa và các dịch vụ và 1 biến đầu ra là chỉ số giá tiêu dùng. Tổng cộng bộ dữ liệu có 252 dòng. Trong đó mỗi dòng biểu diễn các giá trị trong 1 tháng. Lưu ý rằng, tập dữ liệu này gồm các giá trị không cùng scale với nhau và tồn tại nhiều giá trị ngoại lệ. Do vậy, trước khi đưa vào huấn luyện, tập dữ liệu cần được chuẩn hóa và loại bỏ giá trị ngoại lệ.
2.2. Xử lý dữ liệu ngoại lệ
Nghiên cứu sử dụng biểu đồ hộp nhằm loại bỏ các giá trị ngoại lệ trong tập dữ liệu (McGill et al., 1978; Hodge et al., 2004). Hình 1 mô tả biểu đồ hộp của 7 biến đầu vào và 1 biến đầu ra của tập dữ liệu ban đầu. Trong đó, trục hoành biểu diễn các biến. Trục tung biểu diễn các thông tin quan trọng như Giá trị nhỏ nhất, Tứ phân vị thứ nhất, Tứ phân vị thứ hai hay Trung vị, Tứ phân vị thứ ba, và Giá trị lớn nhất của mỗi biến. Theo mô tả ở Hình 1, chúng ta thấy được tất cả các biến đều có giá trị ngoại lệ.
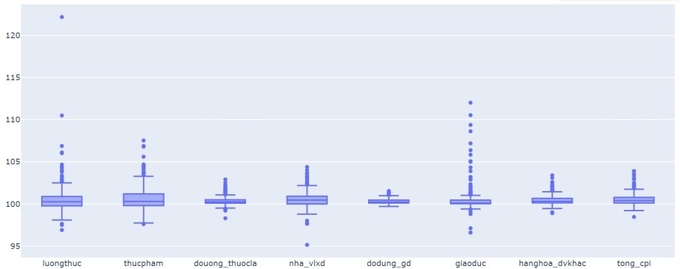
Hình 1: Biểu đồ hộp của mỗi biến trong tập dữ liệu trước khi loại bỏ giá trị ngoại lệ.
Hình 2 biểu diễn biểu đồ hộp của mỗi biến sau khi loại bỏ các giá trị ngoại lệ. Giá trị bị loại là những giá trị nhỏ hơn Giá trị nhỏ nhất và lớn hơn Giá trị lớn nhất. Các biến sau khi xử lý giá trị ngoại lệ đã có sự phân phối đồng đều hơn và ít biến thiên hơn so với trước khi xử lý. Các biến đều có giá trị trung bình nằm gần mức . Khoảng biến thiên của các biến đều thu hẹp lại so với dữ liệu ban đầu, chứng tỏ việc xử lý ngoại lệ đã làm dữ liệu tập trung và cân đối hơn. Việc loại bỏ các giá trị ngoại lệ giúp làm sạch dữ liệu và cải thiện tính ổn định của các biến đầu. Tập dữ liệu mới này sẽ được sử dụng để đưa vào huấn luyện mô hình mạng nơ-ron nhân tạo ở bước tiếp theo.
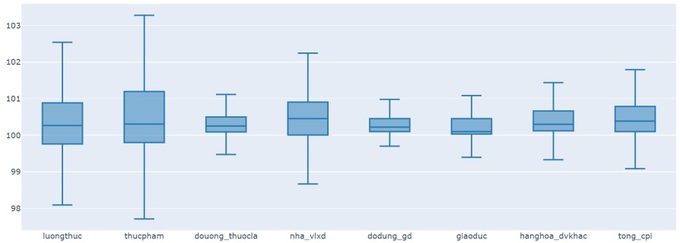
Hình 2: Biểu đồ hộp của mỗi biến trong tập dữ liệu sau khi loại bỏ giá trị ngoại lệ
3. Dự báo CPI bằng mô hình mạng nơ-ron nhân tạo
Trong phần này, bài báo giới thiệu các bước trong quá trình xây dựng, huấn luyện và đánh giá hiệu quả mô hình Trí tuệ nhân tạo. Đầu tiên, chúng tôi sẽ giới thiệu kiến trúc của mạng nơ-ron nhân tạo (Yegnanarayana, 2009). Tiếp theo là thuật toán huấn luyện mô hình và các thông số mô hình. Cuối cùng, chúng tôi đánh giá mức độ chính xác và tin cậy của mô hình sau khi huấn luyện. Các giá trị đã được chuẩn hóa sẽ được chuyển đổi để trở lại giá trị ban đầu.
3.1. Kiến trúc mô hình mạng nơ-ron nhân tạo
Hình 3 mô tả kiến trúc của mạng nơ-ron nhân tạo được sử dụng trong nghiên cứu này. Mô hình gồm có 4 lớp. Lớp đầu vào gồm có 7 nodes tương ứng với 7 biến đầu vào trong tập dữ liệu gồm: . Lớp này sẽ kết nối trực tiếp với 2 lớp ẩn. Mỗi lớp ẩn gồm có 64 nodes. Trong đó, lớp ẩn sẽ kết nối với 1 hàm kích hoạt (activation function) relu trước khi kết nối với lớp kế tiếp. Lớp cuối cùng là lớp đầu ra gồm 1 node, tương ứng với biến . Tất cả các lớp trong mạng đều được kết nối với nhau, hay còn được gọi là fully connected layer.
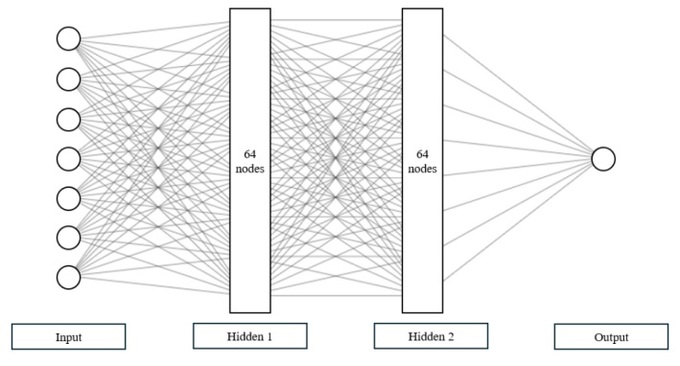
Hình 3: Kiến trúc mạng nơ-ron nhân tạo.
3.2. Huấn luyện mô hình
Tập dữ liệu được chia làm 2 phẩn là: Tập huấn luyện (Training dataset) và Tập kiểm tra (Testing dataset) với tỉ lệ tương ứng là . Trong đó Tập huấn luyện được sử dụng trong quá trình huấn luyện mô hình. Tập kiểm tra được dùng trong quá trình đánh giá hiệu quả của mô hình sau khi huấn luyện. Do vậy, để đánh giá hiệu quả của mô hình trong quá trình huấn luyện cần chia nhỏ Tập huấn luyện thêm thành 2 tập: Tập huấn luyện và Tập xác thực (Validation dataset) với tỷ lệ tương ứng là 0.8 và 0.2.
Mô hình mạng nơ-ron nhân tạo này được thực thi trên ngôn ngữ lập trình Python trên nền tảng Google Colab với cấu hình GPU Tesla K80. Trong nghiên cứu này chúng tôi sử dụng thuật toán tối ưu Adam với learning rate là 0.001 và số lượng epoch là 200.
3.3. Kết quả huấn luyện
Hàm đánh giá độ sai khác giữa giá trị thực tế và giá trị dự đoán được gọi là hàm mất mát (Zhao et al., 2016). Trong nghiên cứu này, chúng tôi đã sử dụng một hàm mất mát là sai số bình phương trung bình (MSE). Hàm được định nghĩa như sau (Toro-Vizcarrondo et al., 1968; Gilroy et al., 1990):
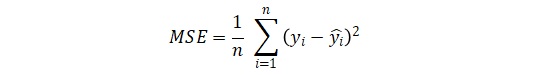
Trong đó, n là số lượng điểm trong tập dữ liệu, y và yi lần lượt là giá trị thực và giá trị dự đoán của chỉ số CPI. Giá trị của hàm này càng nhỏ chứng tỏ độ sai khác càng ít. Hay nói cách khác, mô hình sau khi huấn luyện dự đoán tốt kết quả.
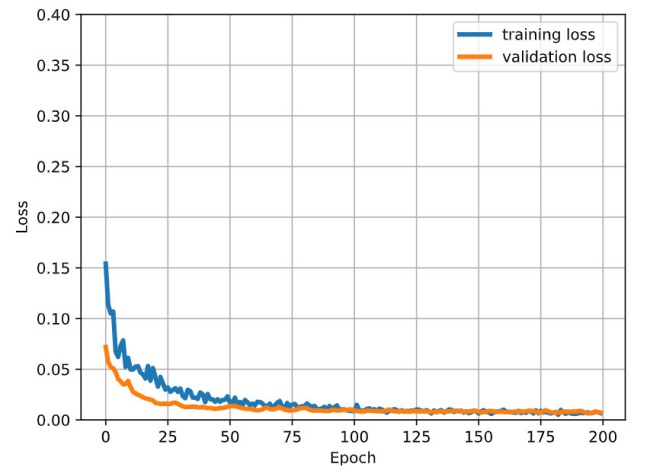
Hình 4: Thay đổi hàm mất mát trong Tập huấn luyện và Tập xác thực khi tăng số lượng epoch.
Hình 4 thể hiện sự thay đổi của hàm mất mát trên Tập huấn luyện (Đường màu xanh) và Tập xác thực (Đường màu cam) khi tăng số lượng epoch. Trong đó, trục hoành thể hiện số lượng epoch, trục tung thể hiện giá trị của hàm mất mát. Như biểu diễn trong Hình 4, giá trị hàm mất mát trên cả 2 tập đều gần về 0 khi epoch tăng dần. Đặc biệt khi epoch bằng 200 thì giá trị này gần như bằng 0. Kết quả này cho thấy mô hình có khả năng dự đoán tốt chỉ số CPI.
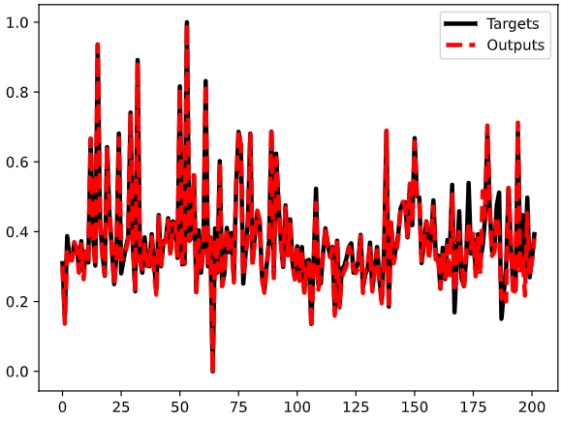
Hình 5: Giá trị thực tế và giá trị dự đoán của mô hình trên Tập huấn luyện.
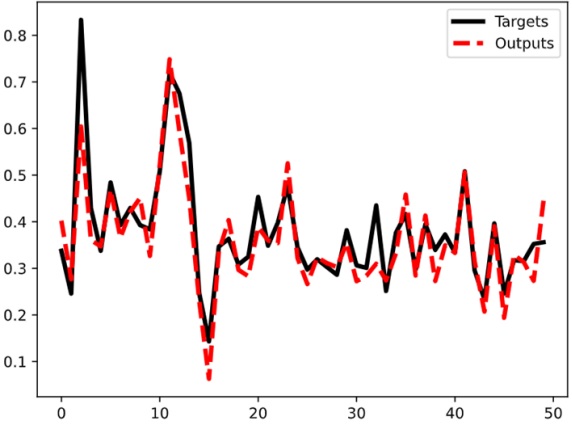
Hình 6: Giá trị thực tế và giá trị dự đoán của mô hình trên Tập kiểm tra.
Hình 5 và Hình 6 biểu diễn giá trị thực tế và giá trị dự đoán của mô hình trên cả 2 tập dữ liệu là Tập huấn luyện và Tập kiểm tra. Trong những hình này, đường màu đen thể hiện giá trị thực, đường đứt gạch màu đỏ thể hiện giá trị dự đoán. Trong hình 5, chúng ta dễ dàng nhận thấy rằng đường đứt gạch màu đỏ gần như trùng với đường màu đen. Kết quả này cho thấy mô hình cho mô hình dự đoán khá tốt trên Tập huấn luyện. Kết quả dự đoán trên Tập kiểm tra đạt độ chính xác không cao như biểu diễn trên Tập huấn luyện. Đường đứt gạch màu đỏ vẫn bám sát xu hướng biến thiên của đường màu đen nhưng vẫn có sự sai khác giữa hai đường. Tuy nhiên, như mô tả trên Hình 6, sự sai khác này không đáng kể. Lưu ý rằng, mô hình chưa được huấn luyện trên Tập kiểm tra. Do vậy, kết quả này cũng thể hiện mô hình sau khi huấn luyện dự đoán CPI với độ chính xác cao. Kết quả trên Hình 5 và Hình 6 có thể được làm rõ khi xem xét giá trị của hàm sai số bình phương trung bình (MSE) của mô hình. Trên Tập huấn luyện và Tập kiểm tra, giá trị MSE của mô hình lần lượt là và . Hai con số này cho thấy MSE tổng thể của mô hình khá thấp, thường được coi là một dấu hiệu tích cực.
4. Kết luận
Trong nghiên cứu này ứng dụng Trí tuệ nhân tạo trong việc dự đoán chỉ số giá tiêu dùng (CPI) tại Việt Nam. Đầu tiên bài báo tiền xử lý dữ liệu để loại bỏ những giá trị ngoại lệ trước khi đưa vào mạng nơ-ron nhân tạo. Nhóm tác tả cũng giới thiệu các bước chính của quá trình dự báo gồm: Xây dựng kiến trúc mạng nơ-ron, Huấn luyện mô hình và Đánh giá mô hình. Trong đó, mô hình được huấn luyện trên Tập huấn luyện và Tập xác thực. Tập xác thực được sử dụng nhằm đánh giá mô hình trong quá trình huấn luyện. Mô hình sau khi huấn luyện được đánh giá trên Tập kiểm tra. Kết quả dự báo của mô hình được trực quan hóa thông qua việc biểu diễn kết quả dự báo trên cả Tập huấn luyện và Tập kiểm tra. Kết quả dự báo khá khớp với kết quả thực tế trong cả hai tập dữ liệu. Kết quả tương tự cũng được kiểm chứng thông qua biểu đồ hồi quy. Hơn nữa, nghiên cứu sử dụng hàm sai số bình phương trung bình để định lượng kết quả dự báo. Giá trị MSE trên hai tập lần lượt là và . Giá trị này đều khá thấp cho thấy hiệu quả dự báo của mô hình tốt và ổn định.
TÀI LIỆU THAM KHẢO:
[Dinh, 2020] Dinh, D. v. (2020). Forecasting domestic credit growth based on arima model: Evidence from vietnam and china. Management Science Letters, 10(5), 1001-1010.
[Nyoni, 2019] Nyoni, T. (2019). Arima modeling and forecasting of consumer price index (cpi) in germany.
[Nahm, 2015] Nahm, D. (2015). The effects of new goods and substitution on the korean cpi as a measure of cost of living. International Economic Journal, 29(1), 57-72.
[Álvarez-Díaz and Gupta, 2016] Álvarez-Díaz, M. and Gupta, R. (2016). Forecasting us consumer price index: does nonlinearity matter? Applied Economics, 48(46), 4462-4475.
[Al-Tamimi et al., 2011] Al-Tamimi, H. A. H., Alwan, A. A., and Abdel Rahman, A. (2011). Factors affecting stock prices in the uae financial markets. Journal of transnational management, 16(1),3-19.
[Hu et al., 2013] Hu, Z., Bao, Y., and Xiong, T. (2013). Electricity load forecasting using support vector regression with memetic algorithms. The Scientific World Journal, 2013(1), 292575.
Phạm Gia Huy - Trương Quốc Trí
Trường Đại học Văn Lang




email: [email protected], hotline: 086 508 6899
 Tag:
Tag:









